
A web archive is a web.archive.org project that stores different versions of all sites from the moment they were created, provided that there is no prohibition on saving the resource. Due to the presence of saved copies in the web archive, site recovery is available even in the absence of a backup.
What Is Web Archive?
The web-archive is a kind of free time machine that allows you to go back months or years ago to see what the resource looked like at that time. At the same time, each site retains numerous versions from different dates, which depend on visits to the project by crawlers of the web archive. Popular sites can save thousands of versions that are updated daily many times throughout the project’s lifetime:

The web archive was founded in early 1996 and since then it has saved over 330 billion web pages, including 20 million books, 4.5 million audio files and 4 million videos, which occupy more than a thousand terabytes. Every day the site is visited by millions of users, and it is included in the TOP-300 of the most popular projects in the world.
History of the creation of the Internet archive
Wayback Machine is one of two main archive.org projects. This non-profit service was created in 1996 by Brewster Cale. The site time machine has a clear goal: collecting and storing copies of resources along with all content to allow free viewing of non-existent or unsupported pages in the future. Since 1999, the robot began to capture also audio, video, illustrations, software.
The base of the modern archive has been collected for 20 years, it has no analogues. The statistics are impressive: to date, the service has 279 billion pages, 11 million books and articles, 100 thousand programs and a million pictures.
Do you know? Web site archives often have legal problems due to copyright infringement. At the request of copyright holders, the library removes materials from public access.
How To Use Web Archive?
The service is very convenient to use. The step-by-step instruction is as follows:
1. Go to the main page of the archive.org.
2. Enter the name of the site you are interested in in the field and press Enter (in our case, this is https://techcrunch.com/ ).

3. Under the specified domain name the basic information is shown: when the project history begins, how many casts does the site have. The example shows that the resource was first archived on September 30, 2017, the library stores 43 archive copies of it.
4. Further, we pay attention to the calendar – the dates of creation of the casts are marked in blue. Each of them is available for viewing: you only need to select the year, month and day of storage. We want to see how the site looked before: let’s say, February 3 of this year. Hover over the blue circle and click on the save time. It can’t be easier!

5. If you wish, you can get general information about the web project – you need to click the Summary button above the chronological table and calendar or familiarize yourself with the site map (Site Map button).

The algorithm of actions can be reduced. To work with the service directly, type in your browser bar
https://web.archive.org/web/*/https://url.
In our case, this
https://web.archive.org/web/*/https://techcrunch.com .
How Can I Generate Free Content Using Web Archive?
The method is based on the fact that every day dozens of websites/domains expire. So, the content of most of these resources is of no value to those who created and abandoned them, and even less so for others. But it is possible that, among this pile of rubbish thrown into the trash of history, you will find your gold nuggets. You just need to browse the disappeared sites and choose decent texts. If at least one copy of such a site has been preserved in the web archive, you are lucky.
Content from dead sites is already out of sight of search engines, (which means unique). And you can become the legal owner of such content by pulling it from the bowels of the web archive. Search engines will perceive it as new and unique. Of course, if during the life of the old site this content was not managed to be brutally repackaged. Therefore, you should always check it for plagiarism.
But first, you need to find the right website/domain. I would advise you to find some valuable expired domains. Here is a complete guide on How to Find Expired Domains: A Detailed Study.
Let’s start by working on an expired domain that has some decent content– https://basicblogtalk.com/
Step 1: Run basicblogtalk.com on archive.org

As you can see from the calendar, the website has been dead right after March 2019. So, the last snapshot of basicblogtalk.com is from March 2019 with some valuable set of contents that I will be using as fresh content.

The next step would be to search a few pieces of content and look for plagarism.
Step 2: Look for Plagiarism
There are a number of free tools that you can use to check a piece of content for plagiarism. I personally prefer using Quetext.com, which is free for content upto 500 words. Since I am using the paid version of Quetext, I am free to explore any length of the content.
Now, I simply scroll down to a few posts.

As you can see clearly from the image that the post- 7 working tips to become an Insanely Productive Blogger was posted on October 24, 2017. Since this is a general post about how to be a productive blogger, I can definitely use this up on my website.
Note: There is no point of adding posts that have no value in 2020. An example would be- Best smartphone for 2017. You need to smart enough to know the value of the content you are about to post.
Now you simply run this post on quetext.

As you can see clearly that the post turns out to be fresh. So, I quickly run a few other posts and check for plagarism.
Turns out out of 7 posts searched through Quetext, I was lucky enough to get all fresh posts. So, the next step would be copy these posts on-to my new site (or the same expired domain that you recently acquired).
The bad news is for those who plan to simply find the site’s archive and download it in the usual way: the pages look like static HTML files, and there are too many of them to do this manually.
If there are around a 100 posts on archived by archive.org, it would be a hectic job to copy paste each of them one-by-one.
You can solve the problem with the help of a ruby script.
Step 3: Install “Ruby.”
If you have already installed Ruby on your PC, you can skip this step and move on to step 4.
You can simply download and install Ruby from here. Its a simple two click process and there is nothing technically involved.

After the installation is done. You need to install the base files.

Step 4: Install the script
Now that you have installed Ruby, the next step is to download this script.
Once downloaded you simply need to follow the next steps.
Open CMD, you can simply click Start, and type CMD and open the Terminal.

Now that you have opened Comand Terminal.

FOR THOSE WHO ARE FACING: COMMAND NOT RECOGNISED
UPDATED: 23rd June; CREDITS: Kartik
Before running the below command:
wayback_machine_download https://example.com –to 201934766262
You need to run one command in CMD:
gem install wayback_machine_downloader
Find the location of the downloaded script, for me it is- C:\Users\tbag\desktop\wayback-machine-downloader-master
So you simply go to the desired directory by using: CD desktop\wayback-machine-downloader-master
This must be the final result of youq query-

Step 5: Download all the files of basicblogtalk.com
Now the next step is to download all the files of basicblogtalk.com. As mentioned previously, you can also manually copy paste your articles one by one. This method will simply download all the website’s files to your desktop in HTML format.
Now you need to run the following command:
wayback_machine_downloader https://example.com --to 20100916231334Where https://example.com is your website, which for me is- basicblogtalk.com and the numbers that you see are the timestamps which can be found on your archive.org URL. See the below snapshot.
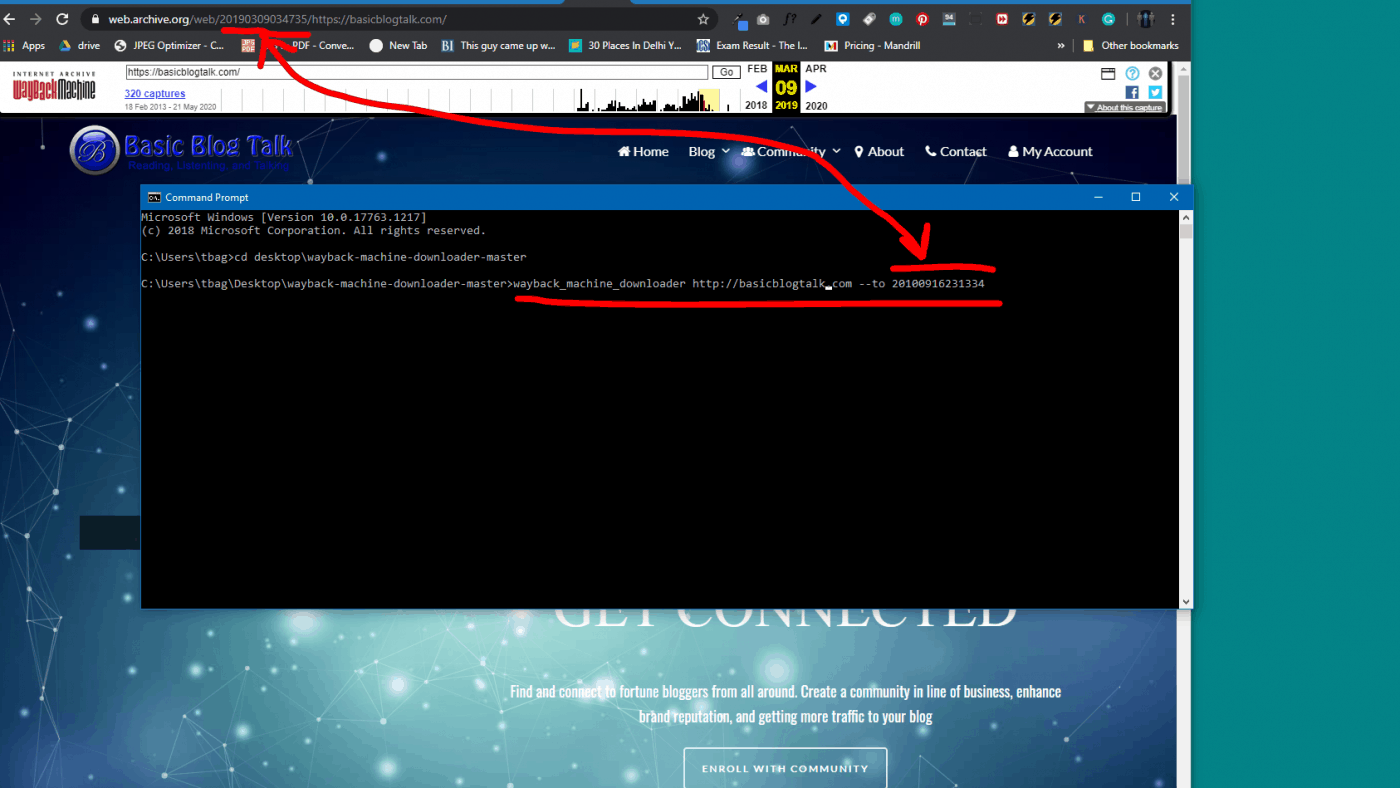
And press ENTER.

The process will soon start and you can wait until all the files have been downloaded. After the files are successully downloaded, you can find them in the /website folder of your script.

If you go inside the website folder, you will find results like this-

So, these are the complete files of basicblogtalk.com until March, 2019.
Now that you have downloaded all the websites files, the last step is to upload them on to your current website.
Step 6: Install HTML Import 2 WordPress Plugin
In order to bulk import your post, you need to install HTML Import 2 plugin on your current website. This is a 100% free plugin.

Step 7: Configure the Plugin
For test purpose, I am uploading the content of my demo site- germanshepherd.care. This is a really important step so carefully read this.
These are some are some standard setting that you need to configure.


I want all the content to be posted as posts, so I have selected posts. By default, the plugin sets it to pages, so you need to change it to posts. You can also configure the categories you want to bulk import the posts too-

Step 8: Uploading website files to plugin default directory
By default, the path is set to- /home/customer/www/germanshepherd.care/public_html/html-files-to-import

Now I have to upload all the files to this directory on my website server.

I open my file manager and create a folder named: html-files-to-import /home/customer/www/germanshepherd.care/public_html/html-files-to-import
After creating the folder upload all the files you downloaded using the Ruby script to this folder.
As there were too many files so, I only uploaded a few files from the downloaded folder.
Upload the files to your server in folder: /home/customer/www/germanshepherd.care/public_html/html-files-to-import and extract them.

Step 9: Importing the files
Now that you have uploaded the files on your server, you need to import the posts using your plugin.

So my files have already been uploaded to the server, so I simply submit and wait.

Note: It will take a few seconds/minutes for uploading the posts. In case you have a large number of files, I would advise you to increase the PHP Timeout limit of your web server or divide the number of uploads into parts.
Step 10: Delete unecessary stuff and add your charm to the post
Now you can go to your posts and find all the posts that you imported from basicblogtalk.com

The last step would be to delete some unnecessary stuff from those posts and get some new images and some on-page SEO.

Now you have some killer free content on your website.
NOTE: I would advice you to schedule 1 post per day with some on-page SEO on the posts.
With these methods you can not only get free content for your website, but this can be a money-making machine for niche affiliate websites that have already expired. All you need is to find some good expired domains and boom!
Opportunities are endless, it depends on how you channelize it. Good Luck and Happy Bloggin!
Do share your views in the comment section below and subscribe to our Youtube channel.








13 Comments
are you sure that this is authentic and there will be no penalty? Can we use this for a genuine company or product based site?
Hi,
If you think from the perspective of copyright law, this is illegal.
I have been testing this method of a number of secondary sites and I have never faced any issues. But I will still suggest you to, not use it on a company website.
If you want to use it, make sure you get some changes to the content, add more value to the content, add new free images, get some SEO done, and then you are good to go!
I agree with Ruby.
This is just a simple trick. But, how you use it, its entire smartness.
Installation
You need to install Ruby on your system (>= 1.9.2) — if you don’t already have it. Then run:
gem install wayback_machine_downloader
Tip: If you run into permission errors, you might have to add sudo in front of this command.
Great tip! Thank you!
First Thank you for awesome article.
I have one Question:
You given “wayback_machine_downloader https://example.com –to 20100916231334″ this command….. in this we select “20100916231334” from archieve.org.
This download only one month data or one year Full data???
Thank you in advance.
Hi Kartik.
All you need to do is- select the time period from the arhive.org website and use that timestamp(from the URL) and it will download the exact copy of the website.
Let me know if you have any more queries.
Regards
Hi Vaibhav,
Thank you for reply….
I found one more Error Like this…
‘wayback_machine_downloader’ is not recognized as an internal or external command, operable program or batch file.
You need to get into the directory properly.
Please go through the steps one by one as mentioned in the video. Don’t miss a single step!
Thank you for the awesome guide 🙂
iI built a website with this technique you shared. Everything is going very well. It was really good information not found elsewhere. Thanks dude.
Cheers! Glad it helped 🙂
I wonder if there is a command to download the articles only (without images, feed, etc.)?